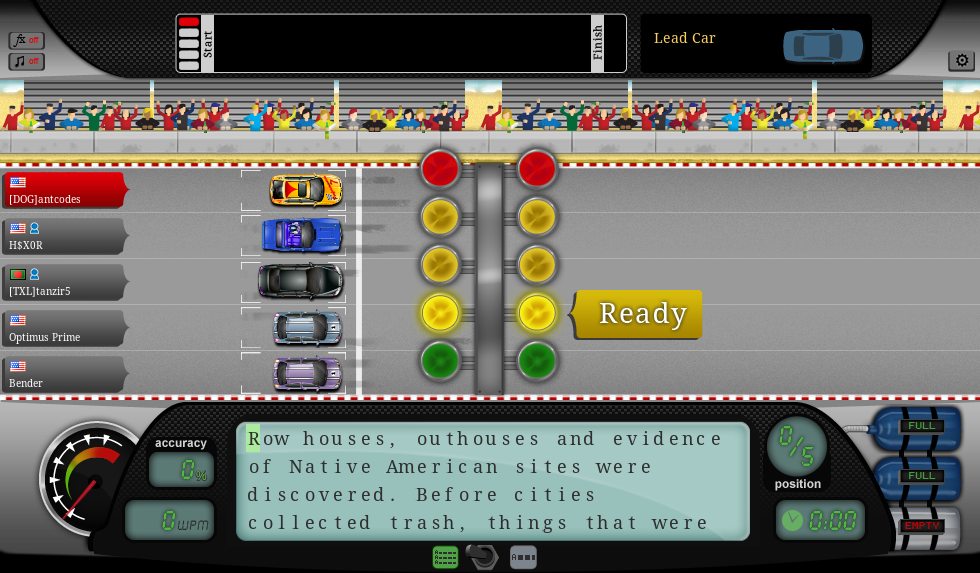
From my last Keybr.com project, I ran into a new website nitrotype.com which has different security mechanisms. Aside from using any Chrome Developer tools, I wanted to test out if I can build a system that would past undetected only a few lines of code.
If you want to view the full code all together, I uploaded it to my Github page: Github Page
After I uploaded the final output, I emailed nitrotype the workaround and also gave them tips on how to prevent cheaters.
The idea was simple, we are presented with text on the screen that we can’t highlight or copy. Python-tesseract is an optical character recognition (OCR) tool for python.That is, it will recognize and “read” the text embedded in images.
It is also useful as astand-alone invocation script to tesseract, as it can read all image typessupported by the Python Imaging Library, including jpeg, png, gif, bmp, tiff,and others, whereas tesseract-ocr by default only supports tiff and bmp.Additionally, if used as a script, Python-tesseract will print the recognizedtext in stead of writing it to a file. Support for confidence estimates andbounding box data is planned for future releases.
Simple eh? Very, I tested a few instances with Tesseract and it worked flawlessly. I created a python application that does everything in this order:
- Take Screenshoot (I use dual widescreen monitors so you’ll need to readjust your ImageGrab.grab numbers accordingly.
- Convert the image text to actual text through bash command
- Replace the punctuations.
- Replay Key Presses.
The Breakdown!
import cv2
import subprocess
import time
import pyscreenshot as ImageGrab
OpenCV
is the most popular and advanced code library for Computer Vision related applications today, spanning from many very basic tasks (capture and pre-processing of image data) to high-level algorithms (feature extraction, motion tracking, machine learning).
pyscreenshot
Takes a screenshot.. You can see where I’m going with this.
This might not be the most conventional way, but it’s the most out of the box way, which earns my vote!
im = ImageGrab.grab([2400, 550, 3350, 780])
im.save('sc.png')
To speed up time, I had the screenshot automatically crop the text area in NitroTire website. Those numbers are based off my dual widescreen monitor setup so you’ll need to change the numbers based on your setup.
You can use: #im.show() to get a faster idea.

bashCommand = "tesseract sc.png output"
process = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)
output, error = process.communicate()
im.save('sc.png')
Here we are going to use tesseract OCR engine to take the sc.png output and transform that into text for us. Pretty awesome stuff.
replacements = {'.':'.,', ',':'.,'}
with open('output.txt') as infile, open('output1.txt', 'w') as outfile:
for line in infile:
for src, target in replacements.iteritems():
line = line.replace(src, target)
outfile.write(line)
Here we are going to do some replacements, I notice that the OCR engine had some issues deciphering between a period and comma. A workaround for this was to replace the period with both period and comma, same for comma.
time.sleep(1)
text = open('output1.txt', 'r').read().strip().replace('\n',' ')
for ch in text:
subprocess.call(["xdotool", "type", ch])
time.sleep(.001)
The last bits, here is the same code I used to emulate a keypress from the keybr project. The difference here is were going to be replacing each new line (\n) with a space ‘ ‘. The last sleep command is to type how fast, were at about 250wpms with .001
Full code below:
Be sure to double check my github for any updated code.
import cv2
import subprocess
import time
import pyscreenshot as ImageGrab
im = ImageGrab.grab([2400, 550, 3350, 780])
im.save('sc.png')
bashCommand = "tesseract sc.png output"
process = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)
output, error = process.communicate()
replacements = {'.':'.,', ',':'.,'}
with open('output.txt') as infile, open('output1.txt', 'w') as outfile:
for line in infile:
for src, target in replacements.iteritems():
line = line.replace(src, target)
outfile.write(line)
time.sleep(1)
text = open('output1.txt', 'r').read().strip().replace('\n',' ')
for ch in text:
subprocess.call(["xdotool", "type", ch])
time.sleep(.001)